Durable Workflows Over Real-Time Data Streams
Write durable, fast, stateful functions that compute over live data streams with full historical context.

As an engineer, if you've ever worked with say IoT data and were trying to do work with your live data stream while trying to use any historical data, you probably designed a pipeline that looked like this:
- Kafka for ingestion
- Flink for ETL
- Lambda/workers for compute
- Timescale for time series storage
- Redis for caching
- Complex glue code to orchestrate it all
Six extra managed services. And you now have to try to optimise away milliseconds of latency between these disparate services, trying to keep up with your edge data sources. And oh yeah, hope you are ready to cover the cloud bill?
Stream processing shouldn't require distributed systems expertise and a 6-figure cloud bill. It should be one lightweight runtime that you deploy where your data lives.
Today, I'm announcing the first alpha version of Slung, a durable workflow engine that brings together stream processing, time series data storage, and serverless compute together on the edge.
What I've Built
With Slung, I went back to first principles. I thought deeply about the problem of streaming data and decided to vertically integrate the entire stack, providing:
- Durable workflows triggered by incoming data streams
- Live query and processing to compute and aggregate live temporal data.
- Built-in TSDB with 1M+ sustained writes/sec and <160ms aggregated query for 1M points
- Sub-millisecond cold starts powered by Wasm
- Edge-optimised, lightweight design (single node, <1 GiB memory at 1B events)
All in a single binary that you can deploy on your edge infrastructure, today.
Why Now?
Edge computing is eating the cloud. IoT devices are getting smarter and now process more data that should be put to work. Latency matters more than ever. Streaming infrastructure is still designed for datacenter-scale distributed systems.
Slung aims to make analytical stream processing lightweight, single-node, edge-native with historical data built-in, just next to your data producers.
Note: this is our first alpha so expect bugs (report them here). I also do not suggest migrating your data to Slung without a back-up to a data lake.
As part of the runtime, I've also shipped a basic Rust workflow SDK alongside a simple Typescript client SDK.
How It Works - Basic Anomaly detection
use slung::prelude::*;
#[main]
fn main() -> Result<()> {
// Subscribe to live stream updates.
let handle = query_live("AVG:temp:[sensor=1]")?;
poll_handle(handle, on_event, 100.0)?;
Ok(())
}
fn on_event(event: Event, alert_threshold: f64) -> Result<()> {
// Compare against baseline in real-time
if event.value > alert_threshold {
for producer in event.producers {
// Write back to producers
writeback_ws(producer, "ALERT: threshold exceeded")?;
}
}
Ok(())
}
Functions are triggered by incoming streams from producers, processes live events, queries historical data, and writes back through several mediums (WebSocket, HTTP for now) in a closed feedback loop.
Architecture
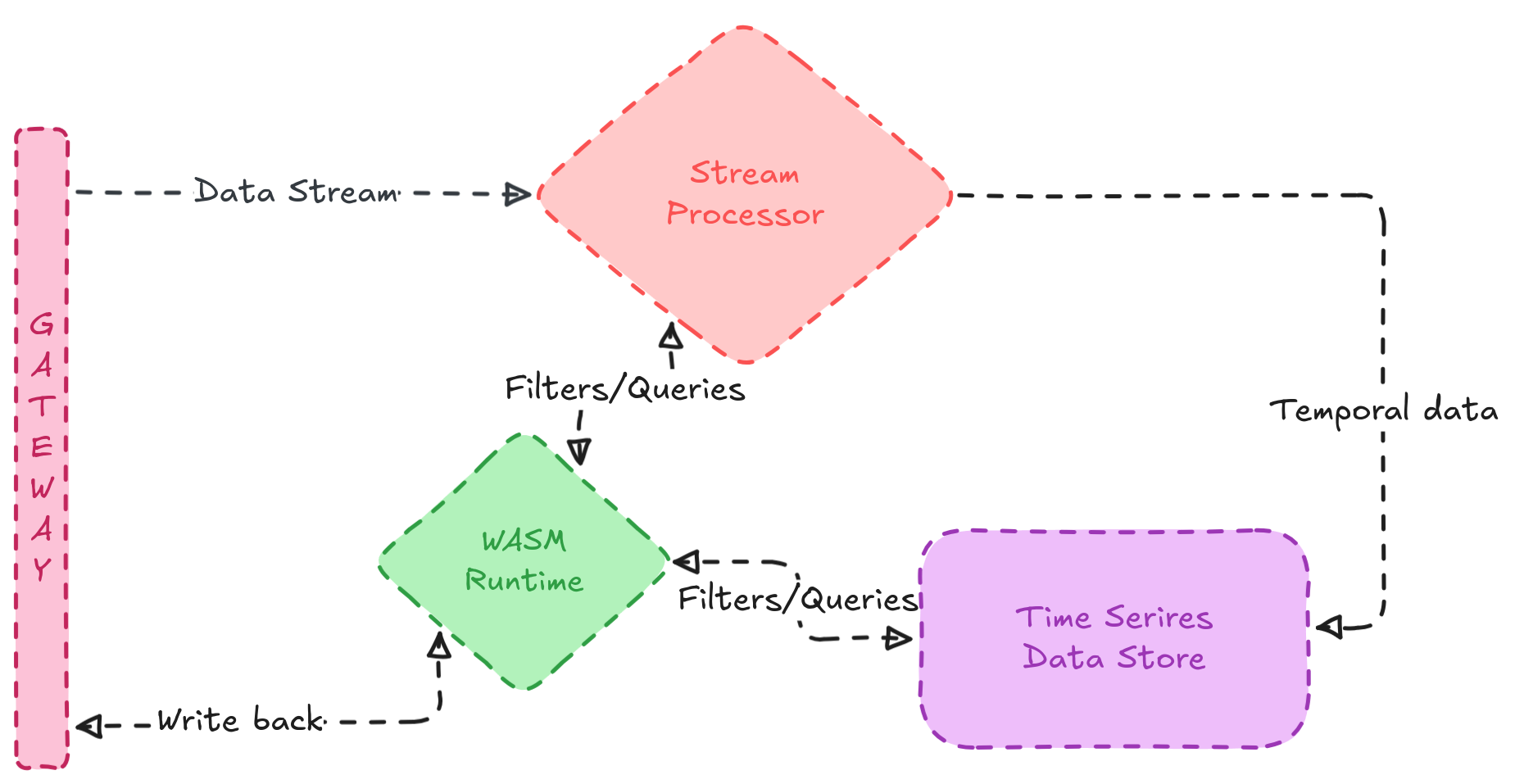
To maintain brevity, this is a high-level overview of the core system architecture:
- Streaming layer
- Websocket ingestion with bi-directional writes
- MPSC ring buffers for live data
- Query DSL -
OP:SERIES:[TAGS]:[RANGE]
- Storage layer
- Series organised skip list memtable for fast writes
- On-disk columnar data format with Gorilla and Delta compression
- Bloom filters for AMQ
- Compute layer
- Deterministic Wasm runtime
- Query live and historical data via host functions
- Triggered by incoming streams and sleeps when idle
Built with Zig

When it came to choosing my tech stack I had to pick between the systems languages I know (Go, Rust, and Zig). Go was clearly out of the picture due to the garbage collector, it really was just me picking between Rust and Zig (which I just started getting familiar with). I wound up choosing Zig because I wanted:
- Control over performance - Everything in Zig is explicit with no hidden allocations.
- Edge-friendliness - Binaries are smaller by default and compile time is exponentially faster with zig.
- Simpler mental model - It was easier to think about system data without needing to battle the compiler.
- C interop - The Zig build system is really powerful and allows me to easily integrate into the rich C ecosystem.
I love Rust, by every means. It has a blossoming ecosystem and is fast as hell, but Zig just seemed like a better option to me for this project. Again, check out our first official SDK, written in Rust.
Use cases
This architecture unlocks use cases that were previously too complex or expensive and I'm quite keen in enabling (not limited):
- IoT Anomaly Detection at the Edge: Run inference on-device, compare against historical baselines with no cloud roundtrip.
- Financial Tick Processing: Process market data with microsecond historical lookups without any external database queries.
- Real-Time Analytics: Aggregate live metrics while querying historical trends using one runtime instead of six managed services.
And it's so lightweight, you really don't need the cloud.
What's next
I have a roadmap of tasks I want to achieve. It's quite high level but points to GitHub issues. But TL;DR, I'll be improving our existing workflow SDK, writing more in Zig, C and Go, as well as more client SDKs expanding the query DSL (to support tumbling window aggs, etc.), object storage sync, and shipping a commercial pipeline builder. If you want to join me, shoot me an email or just open a PR.
Try it
Slung is free and open source (Apache 2.0) and available on GitHub. Star it on GitHub if you find this interesting!
Call for design partners
If you're currently processing 50k+ events/sec with a duct-taped solution I'd love to talk to you.
I'll help you:
- Benchmark Slung against your current stack
- Build a proof-of-concept for your use case
- Get priority support during alpha
I'm especially interested in IoT, high-frequency trading, fintech, and industrial monitoring.
- Book a call (15 or 30 min): cal.com/ewanretor/slung-live
- Email: ewan@slung.tech